
I Built a Warren Buffett Tutor with NotebookLM and Claude.
A local AI app that uses NotebookLM and Claude Code agents to audit your portfolio against Buffett's moat, management, and price filters.

Last week, I was researching stocks when I came across Warren Buffett’s track record.
He ran Berkshire Hathaway for 59 years and turned every $1,000 into $44 million. The S&P 500 turned the same $1,000 into $342,000. That’s 142x ahead of the market.
Average retail trader, same window: $9,000 (Dalbar 2024 report).
If I followed his methodology for the next 50 years, $1,000 becomes $44 million.
No brainer.
But what if I have questions I want to ask him?
How could I do that?
So I decided to build a digital version of him.
A decision system that thinks as he does and answers every question I have.
I did it using Claude Code and NotebookLM.
Let me explain to you how.
The architecture: NotebookLM + Claude Code agents
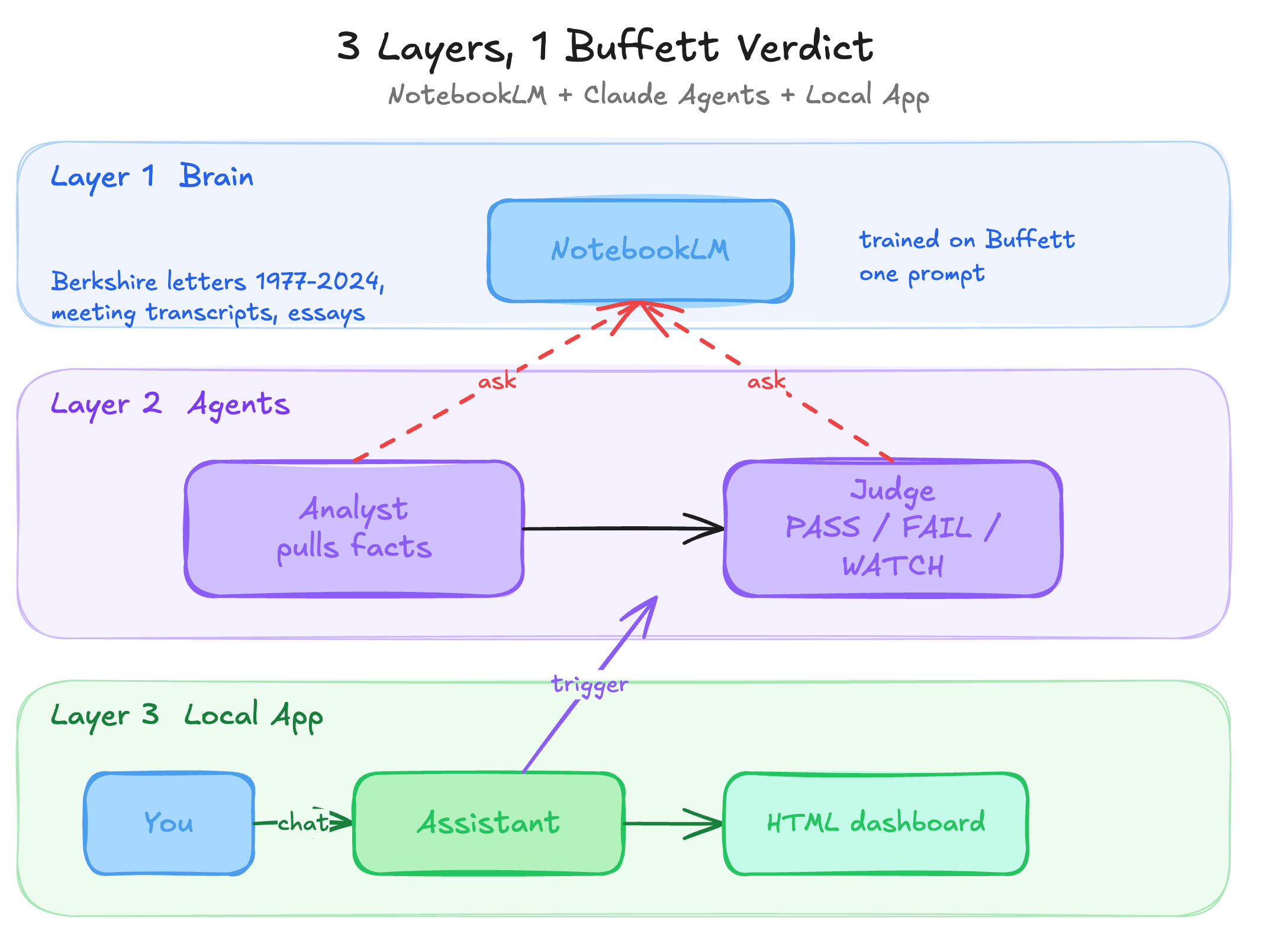
The architecture has 3 layers.
Layer 1 is the brain. NotebookLM was trained on Buffett’s writing. It hallucinates less because it only answers from the sources you give it.
Layer 2 is the decision team. Two Claude Code sub-agents. Analyst pulls the facts. Judge calls it.
Layer 3 is the interface. A local Python app on my laptop. Reads my portfolio CSV, triggers the workflow, and renders verdicts in the browser.
Layer 1: Brain
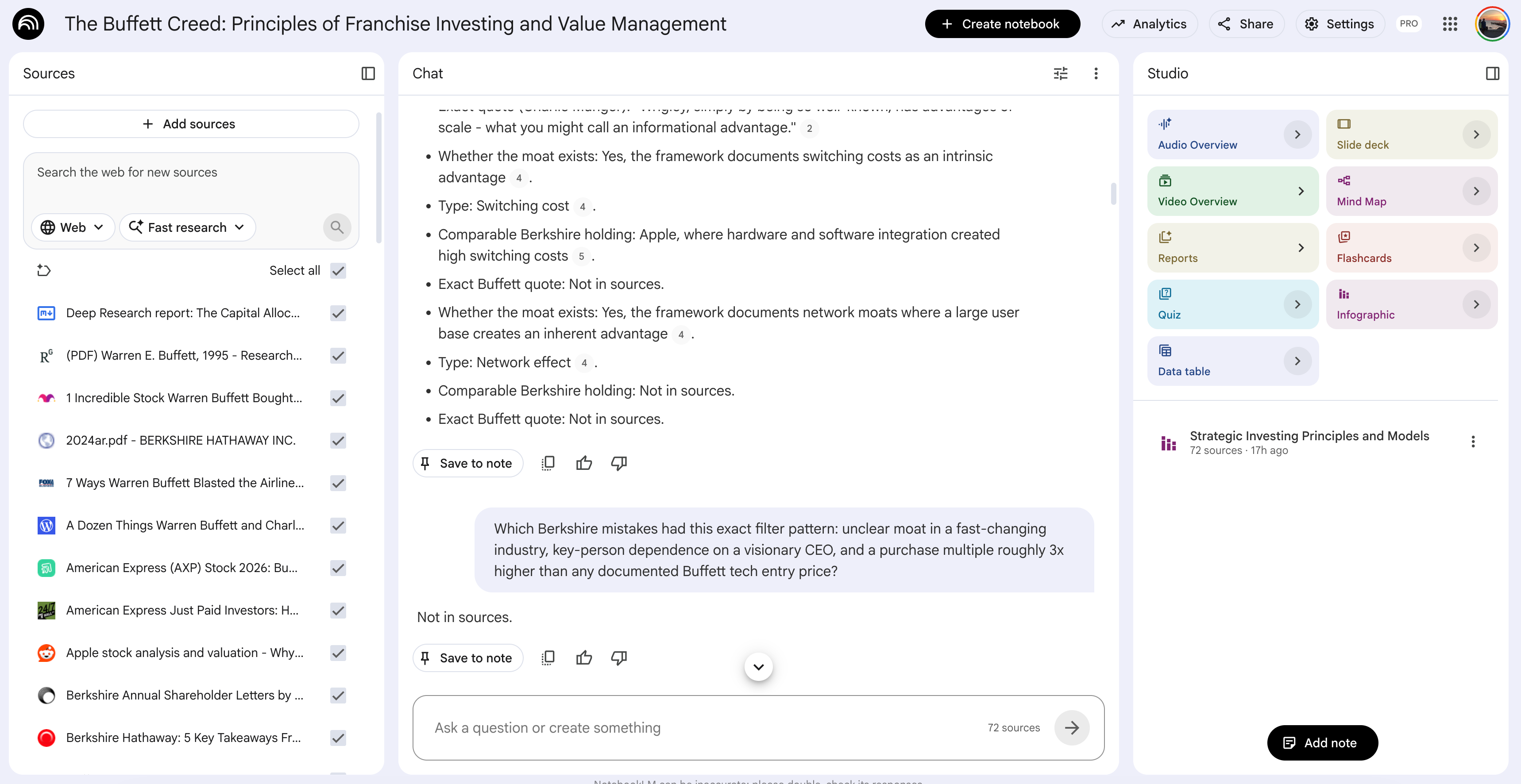
NotebookLM gets trained once with one prompt.
The sources are Berkshire shareholder letters from 1977 to 2024, annual meeting transcripts, and Buffett’s own essays.
I picked NotebookLM because it hallucinates less. It only answers from the sources you give it. If the answer isn’t in Buffett’s writing, the notebook says “Not in sources” and stops. No invented quotes.

This becomes the single source of truth. Every fact the Claude Code agents pull has to come back to this notebook.
Layer 2: Agents

Analyst. Queries NotebookLM for the three filters. Moat, management, price. Returns a structured report per stock.
Judge. Reads the Analyst’s report. Delivers PASS, FAIL, or WATCH. Explains the call in Buffett’s framing.
I picked two agents because one agent agrees with itself. Analyst finds. Judge decides. Separation of duty.
Both agents query NotebookLM directly through the notebooklm-py CLI. No agent uses another’s answer secondhand. Each one goes to the source.
Layer 3: Local App
A local Python app sits on top of NotebookLM and the Claude agents.

We first built it as Streamlit.
The UI was rough, so we switched to React.(just told Claude to switch to a better version, you’ll see.)
It has two different levels.
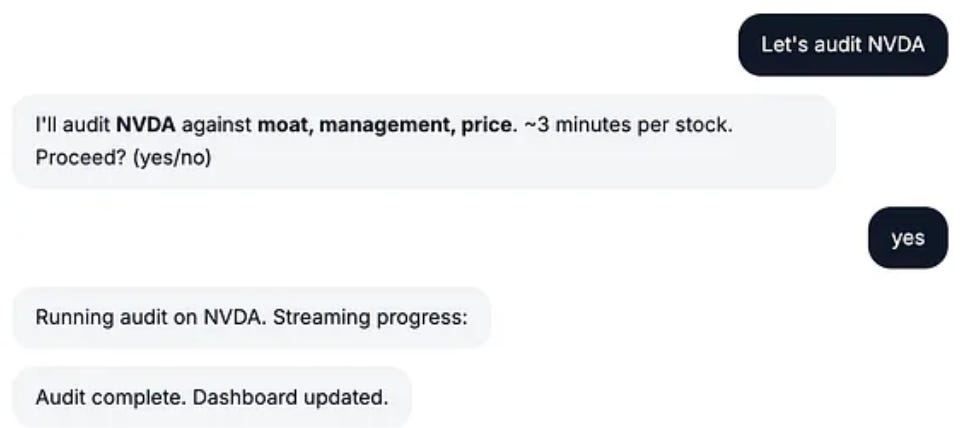
Intent parser. Reads my message, confirms the scope before anything runs. “Audit portfolio.csv against Buffett’s three filters?” If I say yes, it triggers. If I say no, it asks what to change.
Agent trigger. Spawns the Analyst and Judge sub-agents. They query NotebookLM through the notebooklm-py CLI. Verdicts land in an HTML dashboard. Opens in the browser when done.
Why the assistant in front? Because typing the wrong command into a sub-agent run wastes 20 minutes. The assistant catches it in 5 seconds. Confirm first, run second.
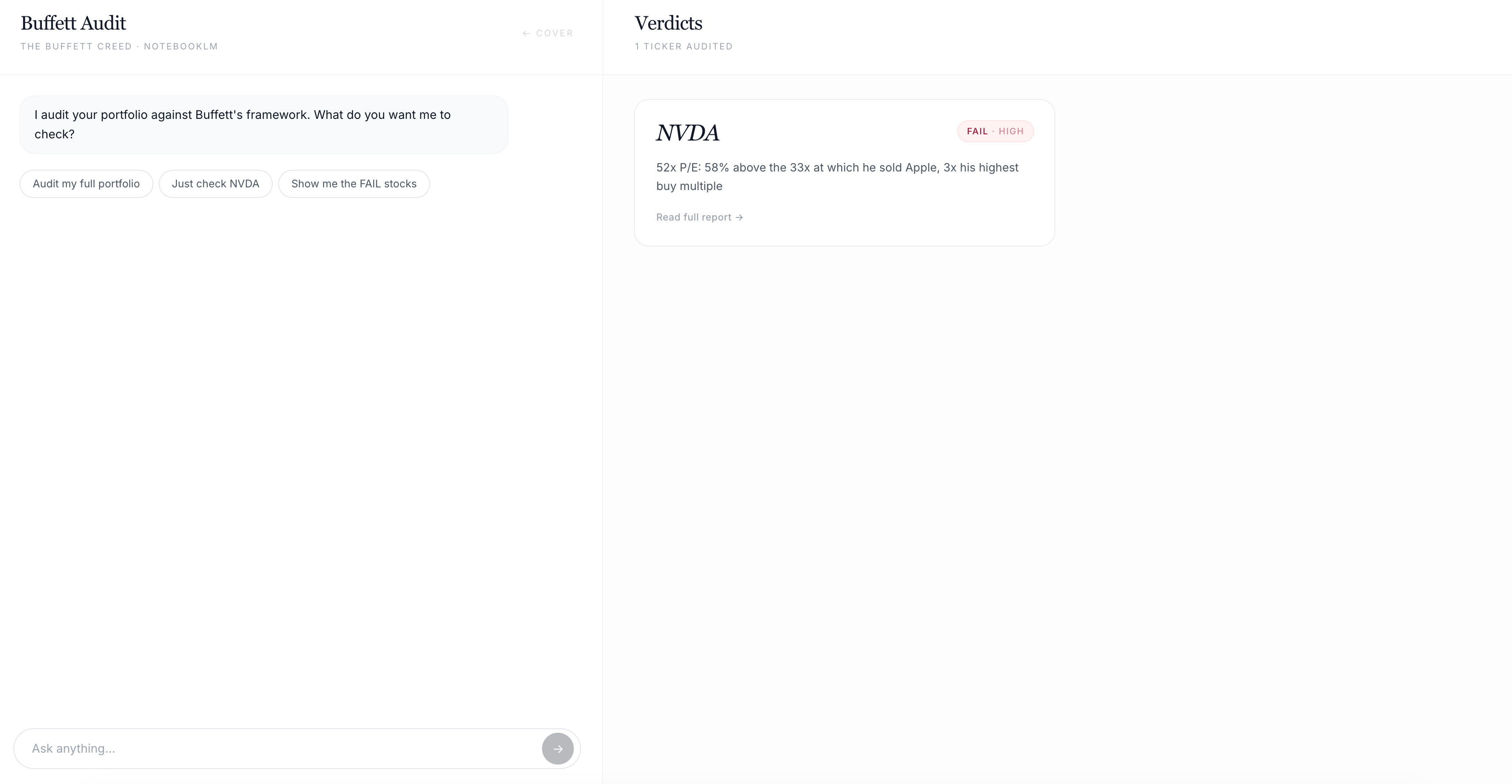
First verdict landed while I was making coffee. NVDA: FAIL. Reason: “Trading at 47x earnings. Mr. Buffett would not own this.”
What will be the result?
Here is what the app looks like on first launch.
Click “Audit” or “Continue Audit” and the split screen opens. The left panel is the chat where you talk to the Buffett-trained NotebookLM.
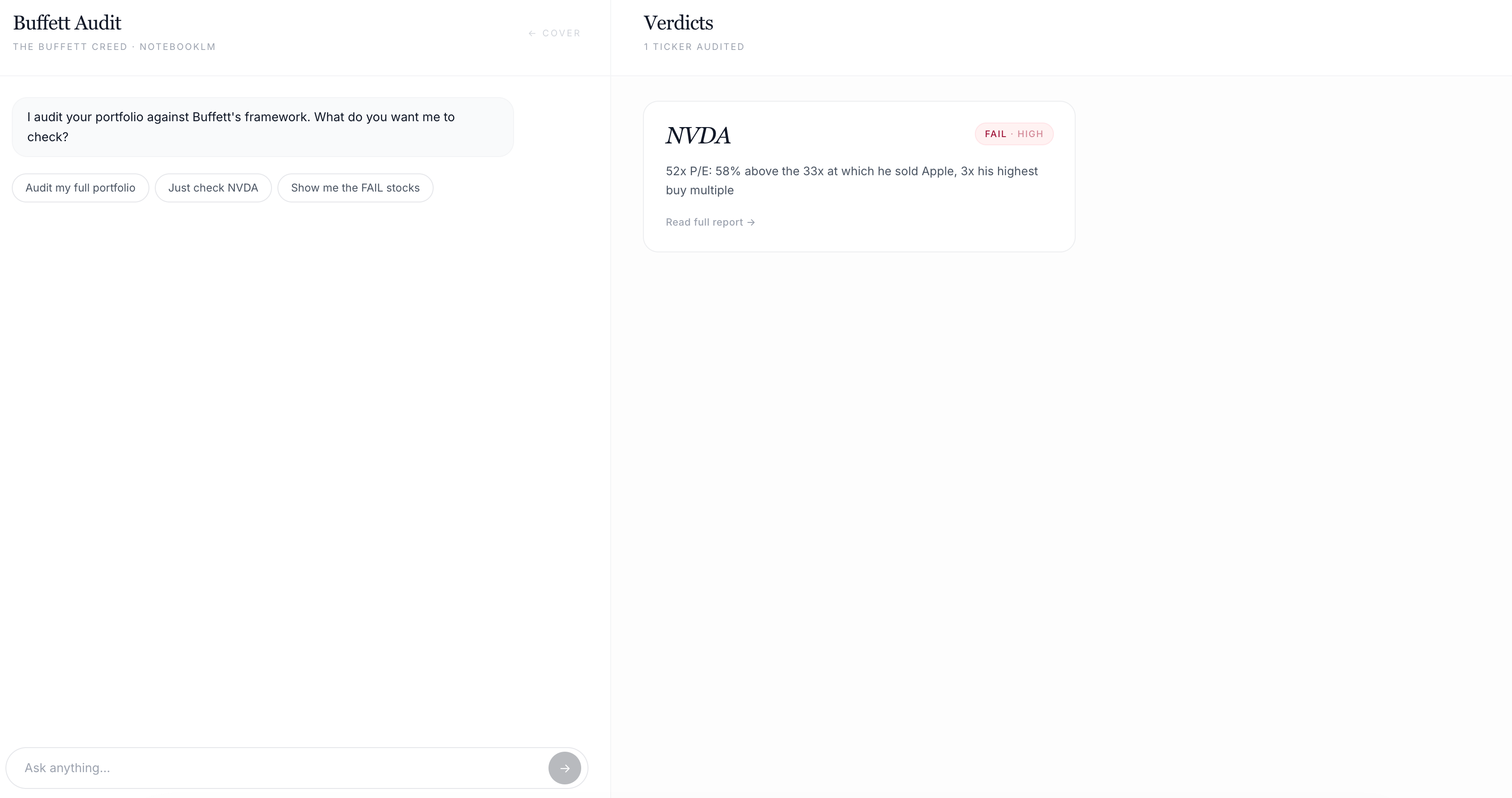
The right panel fills with verdict cards as each stock finishes.
Once the audit is done, the full report renders inside the dashboard.
The best part?
Due to a customization trick I’m going to show you in a second, if our agents ask a question to the NotebookLM trained on Warren Buffett’s history and there is no answer, NotebookLM responds with: “Not in sources.”
The best part? If our Claude agents ask NotebookLM something that isn’t in the Buffett sources, NotebookLM answers “Not in sources” and stops.
So no more hallucinations.
We’ll build it in 4 steps. Let’s start with step 1.